
Head-to-Head: Gemini 3.1 Flash Lite vs. Gemini 3.0 Flash

We are constantly pushing the boundaries of what is possible with automated educational feedback. With the release of Google's Gemini 3.1 Flash Lite, we immediately integrated it into our internal evaluation pipeline to see how it compares to the established Gemini 3.0 Flash.
The results provide a fascinating glimpse into the trade-offs between precision, speed, and cost in the latest generation of Large Language Models.
[!IMPORTANT] Independent Testing: These results are based on our own proprietary testing scripts for marking an exam paper. Both models are currently in Public Preview via Google Cloud Vertex AI.
The Test Case: Marking an Exam Paper
Automating the marking process is one of the toughest tests for an LLM. It requires:
- OCR Excellence: Accurately transcribing diverse handwriting.
- Rubric Adherence: Applying complex, multi-layered marking schemes.
- Evaluative Reasoning: Providing feedback that helps students improve.
The Experimental Data
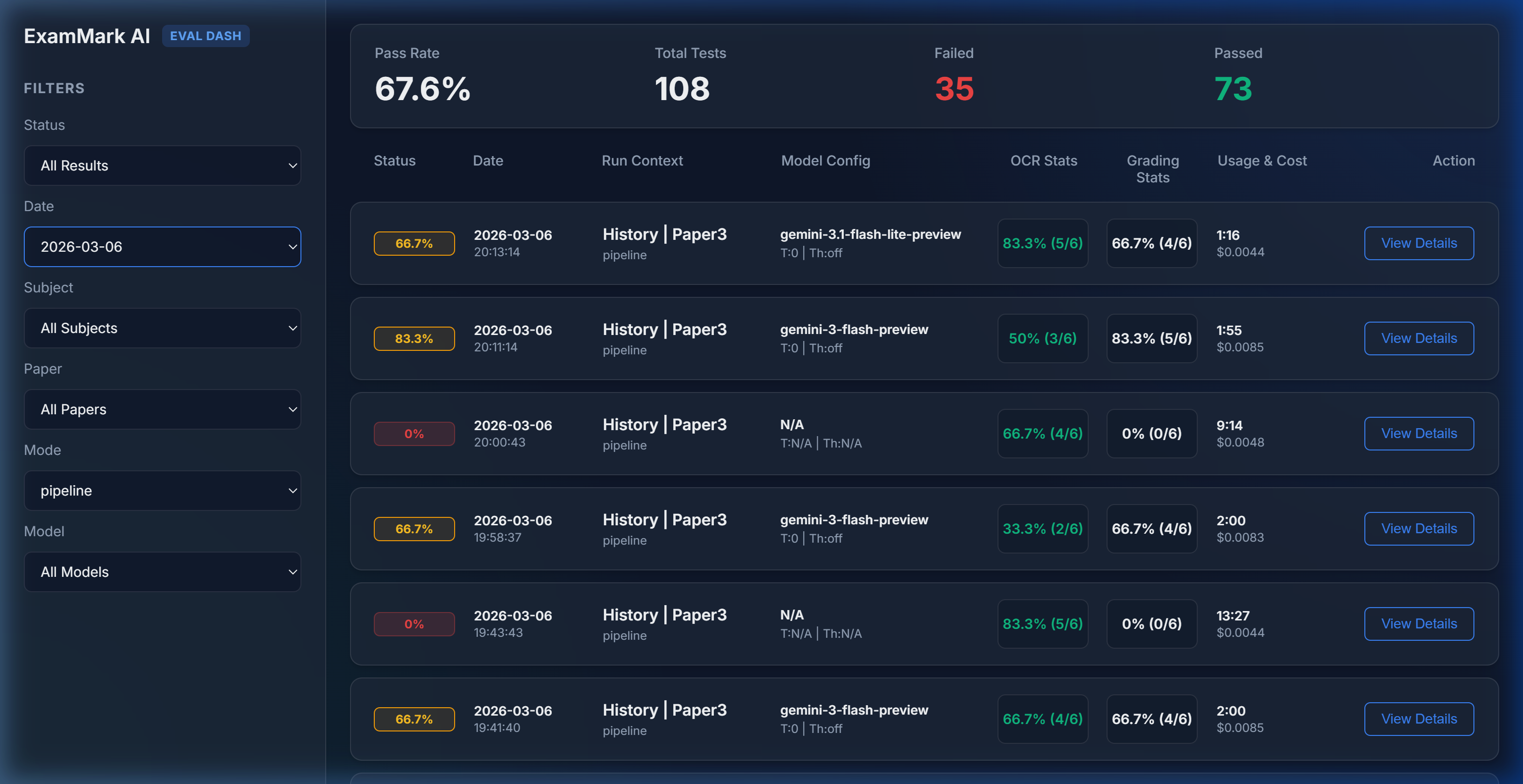
To track these comparisons, I developed a custom evaluation dashboard that aggregates performance data across multiple runs. This project marked my first attempt at running a formal evaluation between different models. It was a fantastic experience learning how to build a robust testing framework for a practical use case, moving beyond simple prompts to systematic benchmarking.
We ran a batch of 16 comprehensive tests comparing the two models on March 6th, 2026. Here is how they stacked up:
| Metric | Gemini 3.0 Flash | Gemini 3.1 Flash Lite | Performance Delta |
|---|---|---|---|
| Accuracy (Pass Rate) | 76.67% | 75.00% | -1.67% |
| Median Cost / Run | $0.0084 | $0.0044 | -48% Cost Reduction |
| Avg. Speed (Total Pipeline) | 154.7s | 115.7s | 25% Faster |
Key Insights
1. Accuracy & Reliability: The Robustness Gap
While the accuracy scores are close, the reliability gap between the two models is noticeable. Gemini 3.0 Flash remains significantly more robust when faced with "evaluative" source questions. These tasks require deep subject-specific context and multi-layer reasoning that the 3.0 Flash model handles with consistent precision.
In contrast, Gemini 3.1 Flash Lite experienced more frequent failures in higher-complexity marking. It occasionally overlooked subtle nuances in the marking scheme that are essential for providing examiner-grade feedback. While its 75.00% accuracy is impressive for its size, it lacks the rock-solid reasoning robustness that its larger sibling provides.
2. Speed: A New Standard for Interactive Feedback
In our user-facing applications, latency is a critical factor for student engagement. Gemini 3.1 Flash Lite is the clear winner here, shaving off nearly 40 seconds per full-script evaluation. This makes it ideal for real-time pedagogical tools where feedback needs to feel conversational and immediate.
3. Cost: Unbeatable Economics
Switching to Gemini 3.1 Flash Lite effectively halves our operational costs. For platform-scale deployments involving thousands of students, this cost reduction enables us to offer more generous free tiers and expand our features without increasing prices.
Final Verdict: Speed vs. Reliability
Based on our testing:
- High-Stakes Assessment & Complex Reasoning: We strongly recommend Gemini 3.0 Flash. It is the more reliable model for tasks requiring high robustness and precise adherence to complex rubrics.
- High-Volume, Lower-Complexity Tasks: Gemini 3.1 Flash Lite is a game-changer for speed and cost, but should be used with a human-in-the-loop or for tasks with lower reasoning requirements.
For my specific use case of high-stakes exam paper marking, I will be sticking with Gemini 3.0 Flash for now. The slight trade-off in speed and cost is well worth the significant boost in reliability and reasoning precision.