
Token Anxiety: The New Developer Friction in the Era of 'Vibe Coding'

We’ve officially entered the era of Vibe Coding. It's that state of Flow where the distance between a thought ("I need a modular dashboard for this data") and a working implementation is measured in seconds, not hours. In this world, intent is the primary language, and the AI is no longer a tool—it's a senior partner that we trust to handle the construction while we focus on the architecture.
But with this new creative freedom comes a new kind of friction: Token Anxiety.
The Upside: 10x Innovation
Before we talk about the friction, we have to acknowledge the breakthrough. Since I started using Vibe coding tools like Gemini CLI and Antigravity, my relationship with code has fundamentally changed:
- Ideas to Implementation: Ideas now become actual code almost instantly, cutting through the usual procrastination. I'm personally coding 10x more than I was before.
- Limitless Exploration: I'm trying things that were previously out of reach—either limited by time or requiring a deep dive into libraries I had no interest in mastering manually. The barrier to "just trying it" has effectively vanished.
The Build-Up: Context & Invisible Quotas
The real friction starts when you begin running out of tokens—especially when you need them most. Having been on the Google AI Pro plan for over 4 months, I've noticed a recurring pattern as the codebase builds up: each new feature and bug fix requires more context, yet the diagnostics for that usage are non-existent.
[!WARNING] The Visibility Gap: We see "100% quota left." But 100% of what? When I started on Google AI Pro, the Gemini Pro refresh windows were roughly 5 hours. Today, they seem dynamic and can spike to 7 days (effectively a full week) without any formal notification. Imagine having a production bug and realizing your model won't refresh for 7 days. Without documented, stable limits, we are flying blind.
Case Study: The Moving Goalposts
To visualize this anxiety, look at the UI comparison below. On Day A, I had a standard 5 Hour Window refresh cycle—the ideal "Vibe Coding" state. By Day B, without any configuration changes or formal notification, that same model hit an unexpected 7-day (6 days, 17 hours as per screenshot) multi-day refresh window.
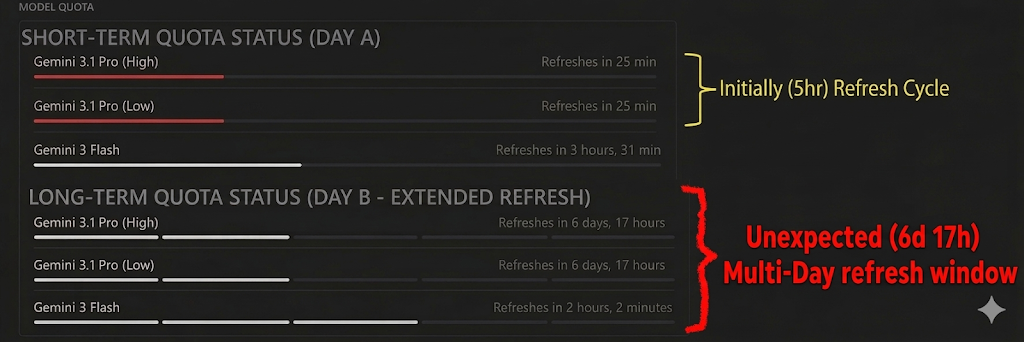
Currently, there is zero visibility into absolute token consumption or the specific amount remaining; the UI only provides a relative percentage. When one action can consume 100K tokens and another 5M, a simple "%" becomes a dangerous abstraction for anyone responsible for production systems. This is especially problematic when planning a day of development—it isn't just a nuisance; it's a critical reliability risk.
This article isn't meant to be a moan at Antigravity or Gemini CLI—it’s about going into this new workflow with your eyes wide open. We are building a strong dependency on external systems in a way we’ve never had before, all in the quest for 10x productivity.
The Dependency Trap: The "Rug Pull" Risk
One of the deepest sources of Token Anxiety is the Dependency Trap. We are currently at the mercy of hyper-scaler LLM providers who have the ability to "pull the rug" at any time. This isn't just about quota; it's about fundamental availability:
- Global Outages: If your hyper-scaler goes down, what is your fallback? Being an AI-assisted coder is powerful, but it's not the same as being a developer who can support production-critical systems without digital co-authors.
- Loosely Worded Policies: When I signed up for Google AI Pro, the promise was "Higher access to Gemini 3.1 Pro." But "higher" is a relative term, not a documented limit. Since joining, I've seen refresh policies shift from hours to days without any formal notification. When the rules are "subject to change based on dynamic availability," you aren't just coding—you're gambling on your vendor's capacity.
- Arbitrary Unavailability: Whether it's a DDOS attack on the API or a provider blocking your access without real notice, the result is the same: your 10x productivity drops back to zero instantly.
Ask yourself: "Can I fix a production bug if I suddenly lost access to my code-assist tools?"
When your productivity depends on a centralized, managed knowledge pool that can change its terms mid-stream, you are accruing a new kind of technical debt. We are witnessing a migration away from the classic open-source community—where experts were "in the wild" and documentation was transparent—toward managed, centralized knowledge pools where the rules are hidden and dynamic.
The Support Gap: Transitioning out of Beta
Currently, tools like Antigravity are still in Beta. This means there is a lack of a specific Google support system for some of these agentic workflows—where can I even raise a ticket? While the developer community is incredibly helpful, there is no one to explain the exact token limits or resolve a quota issue in real-time. But there’s another issue: Model Lock-in. Unlike tools like Claude Code or Open Code that are starting to offer model flexibility, Antigravity currently doesn't allow you to plug in your own models or use a local LLM as a backup. I hope Google would eventually add support for local models—especially the ability to use their own Gemma 4 as a local fail-safe—to ensure we are never truly locked out of our own engineering workflows when the "Context Wall" hits.
[!TIP] What to Expect: As you build and extend your codebase, your token usage will naturally scale up. To maintain a "without limits" development flow, you'll likely need to budget for top-end tiers (potentially equivalent to Google AI Ultra) as costs increase alongside your productivity.
How Do You Mitigate the Risk?
We need a mindset shift. Instead of just being "AI-assisted developers," we are effectively becoming Engineering Leads managing a digital team.
- The Key Man Dependency: Treat your AI agent like a human engineer who didn't show up for work today. If you have a "Key Man dependency" on an agent that engineered half your codebase, what is your plan when its refresh window hits a 7-day wall?
- Production Responsibility: If you are deploying AI-engineered code to production, you better be ready to have the same level of understanding as if you wrote every line yourself. You must be able to fix a production bug without AI assistance, or you are simply building a house of cards.
- Redundancy: Diversify. Understand the limitations of the processes you follow and have mitigations in place to remove your dependency on a single model.
[!CAUTION] The Overnight Agent Trap: With all this in mind, what about those running agents overnight? Are you doing so with full trust in the outcome? Are you comfortable burning through higher-tier tokens without any human interaction or oversight? For most of us, without industrial-grade isolation and guard rails, this is less of a "productivity hack" and more of a reliability gamble. Is that even a practical option for us right now?
Conclusion: The 10x Reality
Despite these frictions, the value remains undeniable. Token Anxiety is the growing pain of a massive shift in how we build software. We are no longer just writing code; we are conducting intent at scale.
The goal isn't to stop "vibing," but to be aware of the "Context Wall." By modularizing our architecture and staying conscious of our dependency, we can keep the 10x productivity while ensuring we don't get trapped by the tool that made it possible.
[!NOTE] Aesthetic Disclaimer: The illustrations in this post are AI-generated parodies inspired by classic corporate culture aesthetics. They are intended as a creative homage to developer archetypes and are not official or licensed artwork from any comic syndicate.